
By looking at data from multiple perspectives, any dataset is transformed into a sea of possibilities
See the Github repo for this project.
This project won second place at the ACDH virtual Open Data Hackathon 2020.
Introduction
The ACDH-CH virtual hackathon 2020 focuses on Open Data. For our project, we were given as main dataset to take into consideration that of the Digital Humanities Course Registry, a platform that provides an overview of the growing range of available teaching activities in the field of digital humanities worldwide (in the words of ACDH-CH). Data and metadata about teaching activities were to be central for our submission, and all was legit except map visualization. All good. We decided to go for a knowledge map.
Knowledge map: an exploration
Since a map visualization would have been the most obvious approach to the given, already quite structured dataset, yet the one not allowed, we decided to try and look at the data from an entirely different perspective. Having been long fascinated by old-fashion hypertext environments, it came natural for us to steer towards an approach that would allow us to see the precious information given as a great amount of possibility, rather than a set amount of knowledge.
For this purpose, we decided to add a layer of wikification on top of the given dataset. With the aid of Wikipedia’s API, we were able to create intricate webs of knowledge spreading from each bit of information given by the DH Course Registry. But let’s start from the beginning.
Visualization
How to visualize all of the above? Dash by Plotly was the tool of choice. The dashboard we created is divided into four panels, and is meant to be interacted with in a clockwise fashion.

We begin in the lower-left panel, where the DH Course Registry data is presented in the form of a table that allows the user to interact with the plot above and filter the courses shown.
The top left panel contains a scatterplot that places DH Courses and Tadirah Entities based on their co-occurences — i.e. courses are closer together the more Tadirah techniques and objects they share. The same applies to Tadirah entities based on the number of courses they are taught in. We compute the entities’ positions by feeding the co-occurence data to the dimensionality reduction technique UMAP. We intend this panel to provide a “semantic map” of the DH registry data landscape. It also serves as the starting point for our knowledge map: once any node of the plot is clicked, the related data and metadata appears in the upper-right panel, where our Knowledge Map takes shape.
Wikification
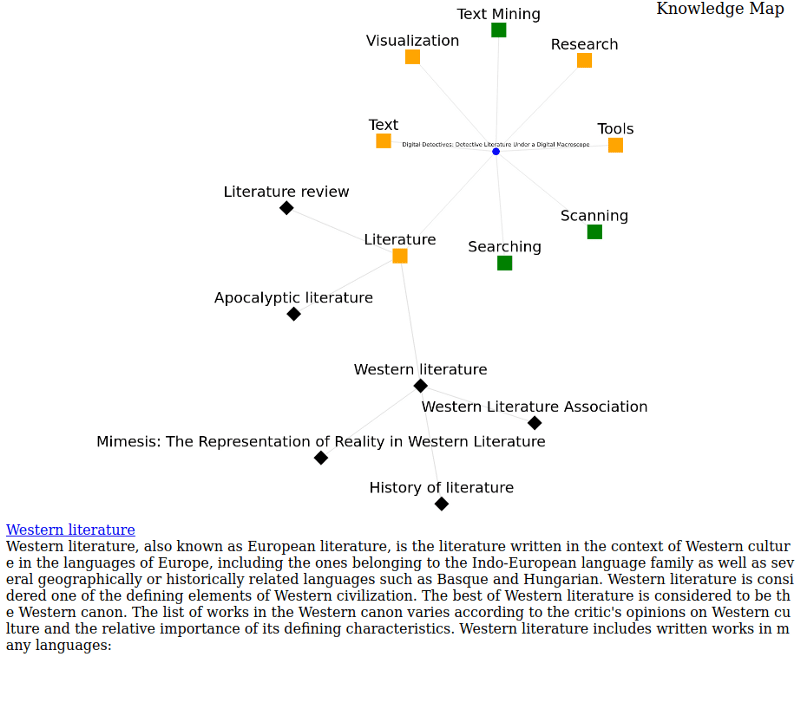
Wikipedia is the depository of knowledge by definition, and a great starting point for rabbit holes. This made it the optimal tool for the creation of the web of knowledge. When clicked, each of the nodes in our knowledge map pull information from the Wikipedia API. The data pulled does not only concern the topic the user has clicked on (e.g. Literature), a summary of which is available in the lower-right panel, but also related topics, that are presented in the generation of a web of related information (Apocalyptic literature, Western literature, Literature review). Each of these new nodes can be used as as many starting points for the generation of new webs in all different directions.
Conclusion
The result of our experiment is the manifestation of a different way to look at data. Taking hypertext environments as example, the given data is in this way not only a set amount of information but a starting point for the creation of a web of knowledge that can help us make unexpected connections.
